一个新设计模式:个人信息台模式
张庆明
本文讨论由笔者和同事杨铁发明的一个新的设计模式:个人信息台模式,它来自于软件开发实践的问题和思考。
本文中设计模式的定义和描述格式请参见Gamma等人的名著《Design Patterns: Elements of Reuseable Object-Oriented Software》。
一、模式名称
个人信息台。
术语“个人”是一个借用词,他的抽象概念代表一个应用目的,例如可以是一个人、或一个角色、或一个功能、或其组合,总之,不要将术语“个人”狭义地理解为一个具体的人。
二、意图
海量对象的集中存储是组织内数据系统集中管理、集成化的要求,而个性化地局部使用信息又是应用本身的特点、实用和性能的要求(基于人的生理局限,我们有充分根据地假设,一个“个人”在一个海量信息池中只有能力使用其中较小一部分内容)。
需要将这一对矛盾协调起来!
三、动机
以下是工程设计实践中经常遇到的若干尴尬:
1、在一个海量信息集中,我们要么很难找到需要的信息,信息太多等于没有;
2、在网络环境中,采用“全部取来,然后再找”的方案是一个复古到文件服务结构的非专业的方案(存储和网络传输效率问题原因,这在Internet上几乎是不可能的)
3、当我们打开一个界面时,我们一片茫然,要么我们什么都不显示,要么我们显示所有的,其中的尴尬实在是一种对信息技术的嘲讽。
考虑在ERP应用中的iterm信息(物料主文件),它是最重要的企业基础数据之一,它的准确性、共享性、一致性要求决定了它必须集中管理维护,一般地,由于全企业使用的物料汇集在一起很多,其对应的物料信息条数很大,一般有几万条到几十万条之多。另一方面,从一个普通业务人员使用的角度,一般只需要使用其中的几百条到几千条。现在的问题是,第一,几十万条信息一并同时呈现在一个具体用户面前需要消耗大量的机器空间和时间;第二,该用户在如此海量的信息中找到自己需要的信息是一件困难的事情。
有两种查询方式:解析查询和浏览查询,解析查询需要对查询目的而言信息集内具有查询线索并与查询规律匹配,例如按分类码、时间、人员查询等;浏览查询要求信息集较小。一般方案采用先解析查询得到较小的结果集,然后再采用浏览查询最后定位。然而,由于应用的多样性,第一步的解析查询方法很难设计,解析选择有其信息规律表达的难点,从而导致第二步浏览查询形如大海捞针,浏览枚举选择在海量信息情况下是困难的。
我们的解决方案是:每个具体用户有一个个人信息索引表(该索引表可以以浏览枚举和解析两种方式组合构造、增量维护),它对应的是自己感兴趣的物料主文件中的子集信息,是个人iterm信息到组织海量iterm信息的映射,当需要物料主文件时,请求个人信息索引表(负责到海量iterm信息表中取对应的iterm项信息)构造出个人iterm信息集然后使用之。
这样,前述两个问题均得到解决:不需要一次同时取得大量(其实大多数无用且带来查找的麻烦)的iterm条数信息,资源(空间和时间)大幅节省,在这个小的信息集中查找所需信息将轻而易举(不论是解析查询还是浏览查询)。
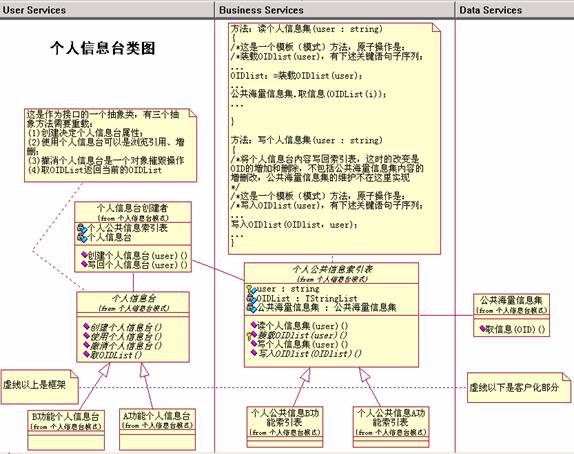
下图给出本方案的设计模型:
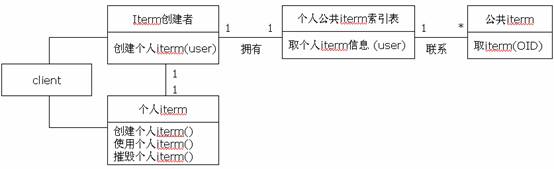
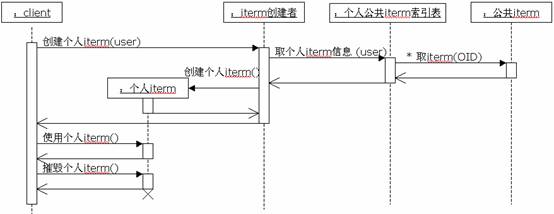
四、适用性
1、可以有各种个人信息台,比如读用信息台,增删信息台等,建议这样标准使用,而不要把使用和维护两种信息台合为一个;
2、建立个人信息维护类,负责个人使用目录的维护;建立个人信息使用类,负责个人信息台的读用;
3、海量存储集的个人维护。对海量对象池的分类维护,删改亦可用个人信息维护台以进行“行过滤”表现权限,个人增加的对象自动拥有删改权限;
4、首次初始信息的省缺显示。我们在进入一个显示界面时,我们可以以此方法定制显示的初始内容。
五、结构
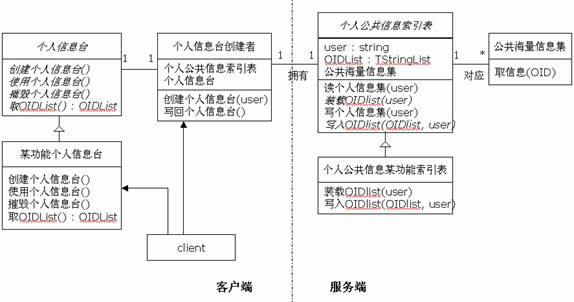 本设计的功能:
本设计的功能:
(1)利用索引表映射海量存储集的一个子集供客户端使用;
(2)包含了索引表的维护操作,但不包含对海量存储集的维护操作;
(3)"某功能"表示不同的客户化功能,一个功能对应一个索引表。
本设计要点:
中间层的索引表负责行选择:利用个人信息和对照表(映射的OID)到海量存储集中去取;
(1)中间层的索引表负责行选择:利用个人信息和对照表(映射的OID)到海量存储集中去取;
(2)客户端的个人信息台负责列选择;
(3)个人信息台创建者是客户与系统的接口,两个操作负责建立一个个人信息台和维护个人信息台(索引表)。
本设计说明:
(1)在类个人公共信息索引表中:
方法:读个人信息集(user : string)是一个模板(模式)方法,原子操作是:装载OIDlist(user),有下述关键语句子序列:
OIDlist:=装载OIDlist(user);
...
公共海量信息集.取信息(OIDList(i));
方法:写个人信息集(user : string)将个人信息台内容写回索引表,这时的改变是OID的增加和删除,不包括公共海量信息集内容的增删改,公共海量信息集的维护不在这里实现。
这也是一个模板(模式)方法,原子操作是:写入OIDlist(user),有下述关键语句子序列:
...
写入OIDlist(OIDlist,user);
...
(2)类个人信息台是作为接口的一个抽象类,有四个抽象方法需要重载:
l创建个人信息台决定个人信息台属性;
l使用个人信息台可以是浏览引用、增删;
l撤消个人信息台是一个对象摧毁操作;
l取OIDList返回当前的OIDList
六、参与者
lclient
——需要使用个人信息台的客户端程序,通常对应某个客户的某个功能
l个人信息台
——提供创建和使用个人信息台对象的接口
l某功能个人信息台
——为client提供个人信息的对象
——创建个人信息台、使用个人信息台、撤消个人信息台、取OIDList的具体实现
l个人信息台创建者
——个人信息台创建者是客户与系统的接口,两个操作负责建立一个个人信息台和维护个人信息台(索引表)
l个人公共信息索引表
——个人公共信息索引表框架,提供了索引表的接口和部分操作实现
l个人公共信息某功能索引表
——某功能的个人公共信息索引表,在某功能下,所有用户其个人信息与公共海量信息集的对应关系信息维护在这里
l公共海量信息集
——公共的所有信息集中存储在这里
七、协作
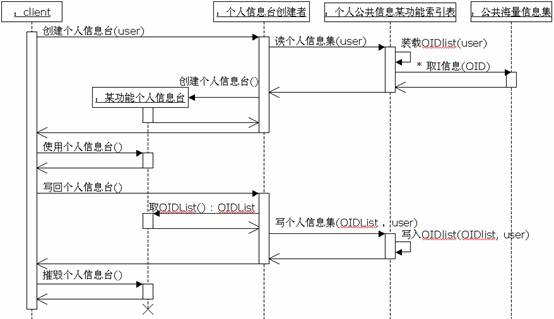 >
>
l当客户端Client需要使用个人信息台信息时,他向个人信息台创建者发出请求,个人信息台创建者到服务端请求个人公共信息某功能索引表,该对象用自己掌握的该用户的公共海量信息集中信息对象的OID,请求公共海量信息集将对应信息取出返给个人信息台创建者,个人信息台创建者用这些信息为初值创建某功能个人信息台。最后将这个某功能个人信息台返给client;
lclient使用某功能个人信息台,有两种使用,读引用和增删。读引用不会修改某功能个人信息台的内容,因此不需要写回;增删用于某功能个人信息台的维护,修改完后要写回;个人使用目录的增删支持两种方式:解析表达式选择和浏览枚举选择;
l写回操作用于维护个人公共信息某功能索引表。client请求个人信息台创建者将个人信息台的内容写回个人公共信息某功能索引表,其间要向个人信息台取得OIDList,最后调用个人公共信息某功能索引表的写个人信息集方法更新了个人公共信息某功能索引表;
lclient使用完个人信息台后,调用其摧毁方法摧毁之。
八、效果
定义实现了一个个人小量信息集到集体海量信息集的映射关系,在概念上,前者是后者的一个子集。
l一方面,信息是集体的,需要共享使用和集中维护管理;另一方面,信息又是由集体中的许多个体产生和使用,然后又汇集在一起。本模式使集中管理和个性使用的矛盾压力得到释放;
l从计算机网络传输、内存空间、执行时间诸方面大大优化;
l使用者只使用自己关心的那个子集信息,实现了个人信息的个性化定制;
l当需要一个省缺信息集,而该集合又无法解析定义时,该方案给出了一个解;
l需要维护索引表及索引表与海量信息集的一致性,这给用户带来工作量,但这为今后使用中的方便性收益所弥补。其实,既然要想得到服务,个性定制开销是必然的;
l增加了索引表的空间开销和索引表到海量信息集信息映射的时间开销,但至少相对于“不知该要什么,干脆全部取来”方案的综合开销要少和聪明了许多,综合地看:第一,开销是无奈的,否则可能会更大;第二,开销是值得的,他方便了用户,实现了信息集中和个性需求的统一;第三,开销是必须的,这是业务功能的提升在资源上的必要投入。
九、实现
(略)
十、一个应用----个人信息台框架
(有关说明略)
二00三年五月十六日